728x90

/petitions/602431 에서 요소는
[ '', 'petitions', '602431'] 3개로 구성된다.
따라서 청원등록번호(602431)를 가져오기 위해서 2번 요소를 가져와야한다.

#각 게시글 별 상세페이지 내용 수집
#청원번호, 제목, 청원자 수, 카테고리, 날짜, 내용 수집
no = 1
cno2 = []
title2 = []
people2 = []
category2 = []
s_date2 = []
e_date2 = []
content2 = []
for i in range(0, len(url_list)) :
print('\n')
print('{} 번째 국민청원 게시글 상세 정보입니다 =================' .format(no))
full_url = 'https://www1.president.go.kr/' + url_list[i]
driver.get(full_url)
time.sleep(1)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
#수집하고 싶은 부분 class 복사
content_all = soup.find('div','petitionsView_left_pg')
#[4]에서 명명해둔 ff_name불러오기(txt로 저장하기)
f = open(ff_name, 'a', encoding='utf-8')
#청원 등록 번호 : url_list에서 번호에 해당하는 것만 가져옴
#'/'을 기준으로 split
c_no = url_list[i].split('/')
cno_1 = c_no[2]
print('1. 청원글번호: ' , cno_1 , '\n')
f.write('\n')
f.write('{} 번째 국민청원 게시글 상세 정보입니다 ==========' .format(no) + '\n')
f.write('1. 청원글번호: ' + cno_1 + '\n')
cno2.append(cno_1)
f.close()
#반복문 종료 확인
no += 1
if no>cnt :
break



no = 1
cno2 = []
title2 = []
people2 = []
category2 = []
s_date2 = []
e_date2 = []
content2 = []
for i in range(0, len(url_list)) :
print('\n')
print('{} 번째 국민청원 게시글 상세 정보입니다 =================' .format(no))
full_url = 'https://www1.president.go.kr/' + url_list[i]
driver.get(full_url)
time.sleep(1)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
#수집하고 싶은 부분 class 복사
content_all = soup.find('div','petitionsView_left_pg')
#[4]에서 명명해둔 ff_name불러오기(txt로 저장하기)
f = open(ff_name, 'a', encoding='utf-8')
c_no = url_list[i].split('/')
cno_1 = c_no[2]
print('1. 청원글번호: ' , cno_1 , '\n')
f.write('\n')
f.write('{} 번째 국민청원 게시글 상세 정보입니다 ==========' .format(no) + '\n')
f.write('1. 청원글번호: ' + cno_1 + '\n')
cno2.append(cno_1)
#청원제목 추출
title = content_all.find('h3', 'petitionsView_title').get_text()
print('2. 청원제목: ' , title , '\n')
f.write('2. 청원제목: ' + title + '\n')
title2.append(title)
#참여인원 추출
people = content_all.find('h2','petitionsView_count').find('span','counter').get_text()
print('3. 참여인원: ' , people , '명', '\n')
f.write('3. 참여인원: ' + people + '명' + '\n')
people2.append(people)
#정보영역 추출
cat_all = content_all.find('ul','petitionsView_info_list').find_all('li')
#카테고리 영역
category = cat_all[0].get_text().replace('카테고리','')
print('4. 카테고리: ' , category , '\n')
f.write('4. 카테고리: ' + category + '\n')
category2.append(category)
#청원시작일
s_date = cat_all[1].get_text().replace('청원시작','')
print('5. 청원시작일: ' , s_date , '\n')
f.write('5. 청원시작일: ' + s_date + '\n')
s_date2.append(s_date)
#청원마감일
e_date = cat_all[2].get_text().replace('청원마감','')
print('6. 청원마감일: ' , e_date , '\n')
f.write('6. 청원마감일: ' + e_date + '\n')
e_date2.append(e_date)
#청원내용
content = content_all.find('div','View_write').get_text().replace('\n','')
print('7. 청원내용: ' , content.strip() , '\n')
f.write('7. 청원내용: ' + content.strip() + '\n')
content2.append(content)
f.close()
#반복문 종료 확인
no += 1
if no>cnt :
break

conda install openpyxl
#출력 결과를 표(데이터 프레임)로 만들기
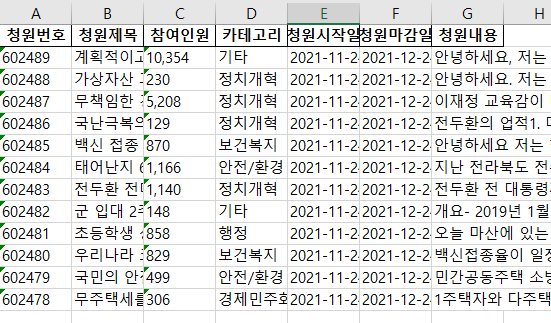
blue_house = pd.DataFrame()
blue_house['청원번호'] = cno2
blue_house['청원제목'] = pd.Series(title2)
blue_house['참여인원'] = pd.Series(people2)
blue_house['카테고리'] = pd.Series(category2)
blue_house['청원시작일'] = pd.Series(s_date2)
blue_house['청원마감일'] = pd.Series(e_date2)
blue_house['청원내용'] = pd.Series(content2)
#csv, xlsx로 내보내기(저장)
blue_house.to_csv(fc_name, encoding='utf-8-sig', index=False)
blue_house.to_excel(fx_name, encoding='utf-8', index=False)
e_time = time.time() #시간측정 종료
t_time = e_time - s_time #소요시간 계산
#요약정보 출력
print('\n')
print('=' *80)
print('총 소요시간은 {} 초 입니다' .format(round(t_time,1)))
print('파일저장 완료 : txt 파일명 : {}' .format(ff_name))
print('파일저장 완료 : csv 파일명 : {}' .format(fc_name))
print('파일저장 완료 : xlsx 파일명 : {}' .format(fx_name))print('=' *80)
driver.close()
728x90
'20대 성장기 > 공부' 카테고리의 다른 글
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [5] 데이터 시각화 (0) | 2021.11.25 |
|---|---|
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [4-3] 판다스 기본문법 (0) | 2021.11.25 |
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [4] 웹크롤링 (0) | 2021.11.23 |
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [3-2] 코드 정리 (0) | 2021.11.23 |
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [3] (0) | 2021.11.18 |