#필요모듈 설치
conda install bs4
conda install selenium
conda install pandas
conda install xlwt
+ 크롬웹드라이버 다운
>>> 포스팅 [3] 참고
from bs4 import BeautifulSoup
form selenium import webdriver
import pandas as pd #판다스는 오타가 많이 나서 편하게 쓰려고 이름 지어줌
import time, sys, re, math, numpy, xlwt, random, os
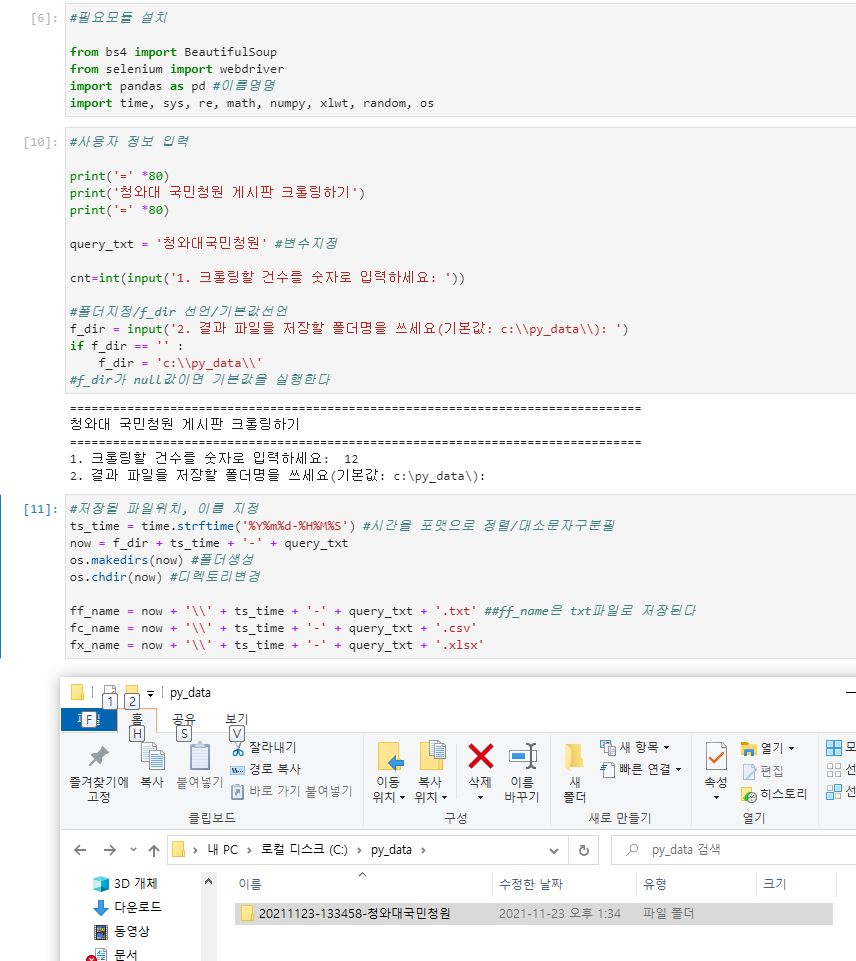
#사용자 정보 입력
print('=' *80)
print('청와대 국민청원 게시판 크롤링하기')
print('=' *80)
query_txt = '청와대국민청원'
cnt=int(input('1. 크롤링할 건수를 숫자로 입력하세요: '))
f_dir = input('2. 결과 파일을 저장할 폴더명을 쓰세요(기본값: c:\\py_data\\): ')
if f_dir == '' :
f_dir = 'c:\\py_data\\'
#저장될 파일위치, 이름 지정
ts_time = time.strftime('%Y%m%d-%H%M%S')
now = f_dir + ts_time + '-' + query_txt
os.makedirs(now)
os.chdir(now)
#총 3가지 파일 저장
ff_name = now + '\\' + ts_time + '-' + query_txt + '.txt'
fc_name = now + '\\' + ts_time + '-' + query_txt + '.csv'
fx_name = now + '\\' + ts_time + '-' + query_txt + '.xlsx'
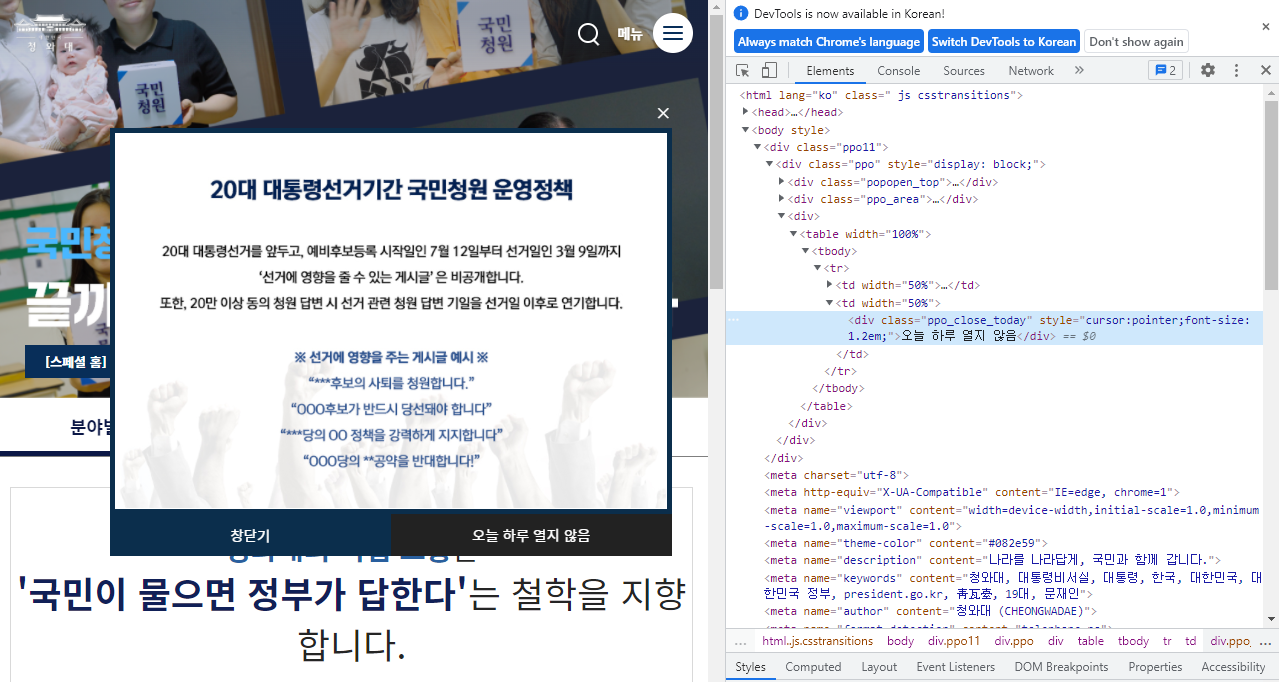
#팝업닫기
오늘하루열지않음 > 우클릭 > 검사
body에서 div 태그(팝업) 확인
xpath 값을 가지고 창 닫기 실행우클릭 > copy > copy Xpath

>>>창열고 팝업닫기
보통 웹에서 태그를 쓸 때, <div> 내용내용 </div> 구조 = element
혹은 <span></span>
<p></p>
<ul>
<li>내용</li>
<li>내용</li>
</ul> #리스트 구조
외
<div id="query">내용내용</div>
<span class="red"></span>
의미 : element를 찾아서 (기준은 xpath) click해라

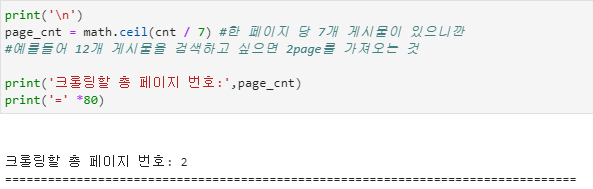
print('\n')
page_cnt = math.ceil(cnt / 7)
print('크롤링할 총 페이지 번호:',page_cnt)
print('=' *80)
#전체 게시글의 주소를 추출하여 목록 만들기
click_count = 1
#각 게시글에서 url 주소 추출해 목록 만들기
url_list = []
count = 0
while click_count <= page_cnt + 1 :
print('{}번째 페이지에서 게시글의 url 정보를 추출합니다 ========= ' .format(click_count))
full_url = 'https://www1.president.go.kr/petitions/?c=0&only=0&page=' + str(click_count) + '&order=0'

#페이지 수만 바꿔서 페이지 이동하도록 while문 구성
#while문으로 +1씩 해가면서 페이지 넘기기
driver.get(full_url)
time.sleep(3)
html = driver.page_source #페이지 소스를 html에 담아놓고
soup = BeautifulSoup(html, 'html.parser') #html 파싱 작업
result_1 = soup.find_all('div','board text') #class가 board text인 것을 다 가져오기(총 3개의 div를 가져옴)
result_2 = result_1[2].find('ul','petition_list').find_all('li')

#3번째 div data 가져오기, class명이 petition list인 ul 태그 가져오기(총 7개), 그 하위의 li 태그 가져오기
-> 전체목록의 7개 하나 하나를 가져와서 result_2에 담는 것
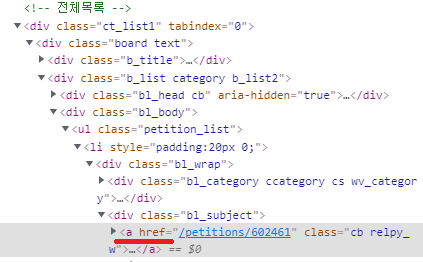
for i in result_2 :
url = i.find('a')['href']
print(url)
url_list.append(url)
count += 1
if count == cnt :
break
#a태그를 찾아서 속성값 href 을 find해라
print('{} 번째 페이지까지 {}건 정보 수집 완료 =======' .format(click_count, count))
print('\n')
click_count += 1
if click_count > page_cnt :
break


'20대 성장기 > 공부' 카테고리의 다른 글
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [4-3] 판다스 기본문법 (0) | 2021.11.25 |
|---|---|
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [4-2] 웹크롤링 (0) | 2021.11.24 |
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [3-2] 코드 정리 (0) | 2021.11.23 |
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [3] (0) | 2021.11.18 |
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [2] (0) | 2021.11.16 |