#사용자정의 함수 만들기
def 함수이름(인수) :
함수가 실행되면 실행될 문장 1
함수가 실행되면 실행될 문장 2
return 출력할 결과값

> 'p'라는 이름의 함수(모듈)을 저장하면 작업 폴더의 위치에 상관없이 불러올 수 있다.
> 웹크롤링에서 사용하는 주요 모듈
- 웹페이지 분석 : beautifulsoup
- 브라우저 제어 : selenium
- 데이터 분석 : numpy, pandas
#패키지 가져오기 import 패키지명
#패키지에서 원하는 모듈만 가져오기 from 패키지 import 모듈명
#디렉토리 변경
import os
#지금 디렉토리는?
print(os.getcwd())
#디렉토리 변경
os.chdir()
#지정된 폴더 내 파일과 목록을 출력하는 함수
os.listdir()
#폴더만들기
os.makedirs()
> 폴더(py_temp2) 만들어서 디렉토리 변경
#txt파일 관리하기
w : 쓰기a : 이어쓰기r : 읽기(기본)
> 디렉토리 py_temp2에 test1이라는 txt파일을 생성
> 내용 추가
#파일내용읽기
f=open("readme.txt","r")
f.readlines()
(base) C:\Windows\system32>conda install pandas
#pandas 설치/엑셀파일 만들 수 있음
#예외처리 : 버그가 생겼을 때 무시하고 진행
try :
예외가 발생할 문장
except 예외 종류 :
발생하면 실행할 문장
else :
발생하지 않았을 때 실행할 문장

no1 = int(input("숫자를 입력하세요:"))
no2 = int(input("숫자를 입력하세요:"))
try :
no3 = no1 / no2
#에러코드 넣어주기
except ZeroDivisionError :
print("0을 나눌수 없습니다. 진짜루 !")
except TypeError :
print("숫자만 쓰세요 !")
else :
print( " 결과값은 : ", no3 )
1. 검색자동화 구현하기
#설치
conda install bs4
conda install selenium
#크롬 버전 확인
>도움말 >크롬정보 >버전 95.0.4638.69(공식 빌드) (64비트)
'크롬드라이버' 검색해서 버전에 맞는 드라이버 다운로드
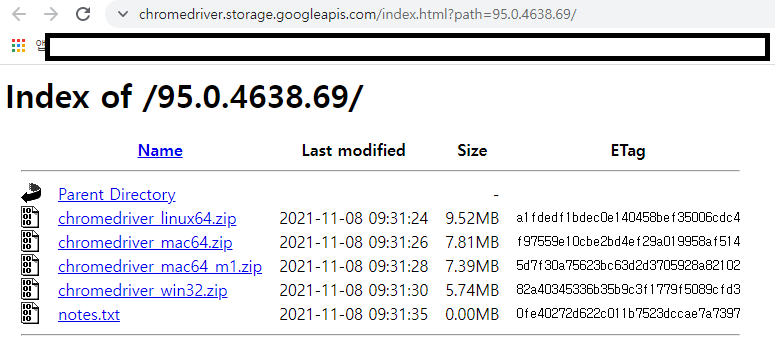
다운로드된 chromedriver 복사해서 사용하고 있는 디렉토리(py_temp2)에 붙여넣기
2. riss 크롤링
>모듈과 패키지 불러오기
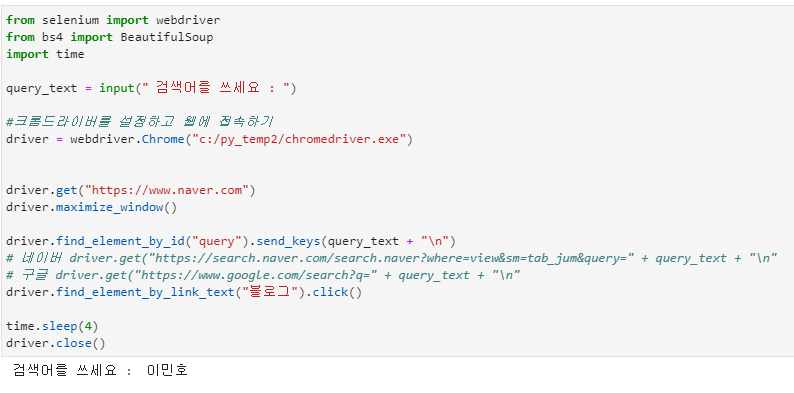
#Step 1. 필요한 모듈을 로딩합니다
from selenium import webdriver
import time
#Step 2. 사용자에게 검색 관련 정보들을 입력 받습니다.
query_txt = input('1.수집할 자료의 키워드는 무엇입니까?(여러개일 경우 , 로 구분하여 입력): ')
print("\n")
#Step 3. 크롬 드라이버 설정 및 웹 페이지 열기
chrome_path = "c:/py_temp/chromedriver.exe"
driver = webdriver.Chrome(chrome_path)
url = 'http://www.riss.kr/'
driver.get(url)
time.sleep(2)
#Step 4. 자동으로 검색어 입력 후 조회하기
element = driver.find_element_by_id("query")
driver.find_element_by_id("query").click( )
element.send_keys(query_txt)
element.send_keys("\n")
'20대 성장기 > 공부' 카테고리의 다른 글
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [4] 웹크롤링 (0) | 2021.11.23 |
|---|---|
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [3-2] 코드 정리 (0) | 2021.11.23 |
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [2] (0) | 2021.11.16 |
| 빅데이터 디자인실무 1급 과정_파이썬 프로그래밍 [1] (0) | 2021.11.11 |
| 논문 쓰는데 필요한 R 프로그래밍 코드 정리 : 기초, 정규화 (0) | 2021.11.05 |